FoundationPose and LangSAM for Robotics
My experience running FoundationPose and LangSAM for monocular RGBD object pose tracking in a tabletop manipulation setting
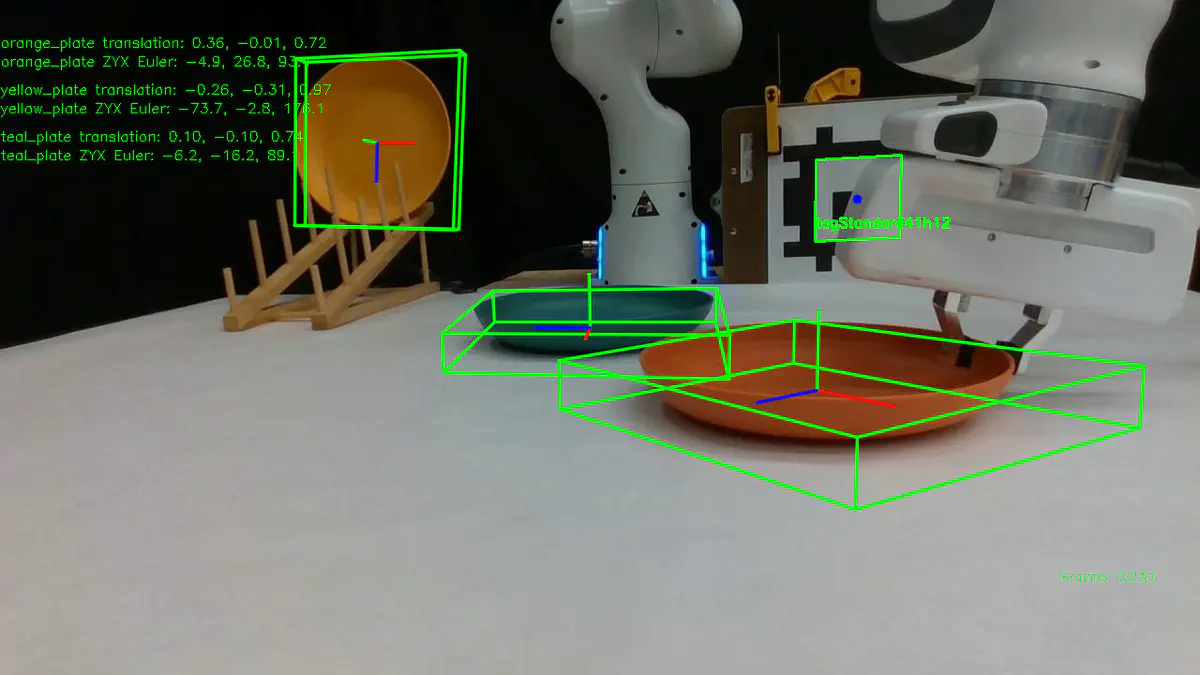 Our tabletop manipulation setup with a Franka arm and FoundationPose tracking of plates
Our tabletop manipulation setup with a Franka arm and FoundationPose tracking of platesThis blog post is about my experience using FoundationPose with LangSAM. It is meant to provide advice for others and qualitative third-party results for reference.
TL;DR FoundationPose combined with LangSAM works somewhat well out of the box, but struggles significantly with small objects and occlusions. I was able to improve results on some tasks by adding an L1 temporal-consistency score on bounding boxes and a few manual data annotations. The model/code has no built-in way of dealing with objects going out-of-frame or complete occlusion, which is a big practical limitation. We’re still exploring newer models and other ways to improve results. Also, see the Conclusion.
Jump to Results on Stack-Blocks
Jump to Results on Stack-Plates
FoundationPose Overview
FoundationPose is a 6D object pose estimation model. It is trained on synthetically-augmented Objaverse objects. At inference time, the model generates multiple pose hypotheses, ranks them, and outputs the rank 0 pose estimate. Unlike previous works, FoundationPose does not need to build a NeRF of the object first.
FoundationPose operates either in a model-based or model-free mode, where “model” refers to a 3D mesh of the tracked object. To run FoundationPose model-free, several reference images of the object need to be supplied. I’ve only tried the model-based version of FoundationPose.
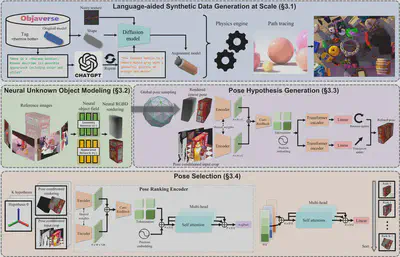
For more details, see the paper, however an in-depth understanding of FoundationPose is not required to use the model. Below is an overview of their method (Figure 2 from the paper).
LangSAM Overview
LangSAM is not a new method or architecture, but actually just code which combines the Segment Anything (SAM) model from Meta with the Grounding DINO open-world object detector. Here, an understanding of what is really going on is helpful for effectively using and modifying LangSAM.
SAM is a powerful segmentation model that can generate pixel-wise segmentations for anything in an image, as the name implies. SAM takes an image and a prompt and outputs a segmentation mask. The prompt can either be points, a bounding box, or a text string. However, Meta has not released a version of SAM with text conditioning. Fortunately, this capability can be reproduced by adding Grounding DINO.
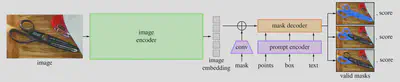

Grounding DINO is an open-world object detector that takes a string of text and outputs bounding box proposals. It was created by fusing a closed-set object detector, DINO, with a text encoder, BERT. LangSAM takes the bounding box proposals from Grounding DINO and feeds them into SAM to obtain a pixel-wise segmentation mask. This blog post explains LangSAM in much more detail.
We have two reasons for using LangSAM:
- FoundationPose requires a segmentation mask of the tracked object(s) in the first frame to initialize pose estimation.
- We wanted a database of object segmentations for a data-augmentation task (not covered in this post).
Off-the-Shelf Performance
FoundationPose requires RGBD video frames, a CAD model, camera intrinsics, and a binary segmentation mask of the tracked object in the first frame.
Below is a visualization of our input video of a VR-teleoperated demonstration of a block-stacking task.
The three views are captured with RealSense D435 cameras running at 1280x720 resolution. The intrinsics matrix is:
$$ K = \begin{bmatrix} 912.0 & 0.0 & 640.0 \\ 0.0 & 912.0 & 360.0 \\ 0.0 & 0.0 & 1.0 \end{bmatrix} $$
The cups, blocks, and plates we used for experiments were purchased on Amazon:
- Cups: https://a.co/d/9PSu2UX
- Blocks (painted after purchasing): https://a.co/d/i5k3pBq
- Plates: https://a.co/d/6hOiS2a
(These are not affiliate links)
The CAD models I created for each of them are available here.
FoundationPose first requires an initial guess for object translation and rotation at every frame. The initial guess is then refined for a set number of iterations (default: 5) to produce the final estimate. For every frame except the first one, the pose estimate of the previous frame is used for initialization. When processing the first frame, FoundationPose generates 240 initial rotation guesses through sampling points and rotations on an icosphere. The first-frame initial guess for translation is obtained through the user-provided segmentation mask.
I modified the FoundationPose code to track all three cubes at once with a simple “for” loop. Below are the first results. I’m only running tracking on the front camera view.
Clearly, there are some issues; the model is unable to track the blocks once they are moved.
FoundationPose with L1 Bounding-Box Consistency
My first idea for improving these results was to condition the pose estimates for every frame on the segmentation masks from LangSAM (vs just the first frame). Essentially, this offloads some of the challenge of object localization from FoundationPose to LangSAM. However, LangSAM doesn’t work perfectly either. Below are the segmentations obtained by running LangSAM on every frame with the prompts (“blue cube”, “red cube”, and “green cube”).
Watch the top right view. When the red cube is manipulated, LangSAM switches to segmenting the blue cube, then the green cube, and eventually the entire stack of cubes. Notably, all the segmentations in the first frame are correct, likely because none of the cubes are occluded by the gripper or stacked.
For each frame, Grounding DINO outputs multiple bounding box proposals, filters them with bounding-box validity and text-alignment score threshold, then outputs the box with the highest text-alignment score. Below is a visualization of the filtered bounding box proposals and scores for the first frame for the prompt “red cube”. The highest scoring box is colored blue.

I implemented a new scoring function to enforce bounding-box consistency between frames. This scoring function (below) is used instead of the prompt-alignment score for all frames except for the first one.
$$ x_t = \arg\min_{\mathbf{x}} \left|\mathbf{x}_{t - 1} - \mathbf{x}\right|_1 $$
Where $\mathbf{x}$ is a vector representing the four bounding box parameters.
In Pytorch:
dist_score = -torch.sum(torch.abs(bbox - last_bbox))
I also lowered the “box_threshold” and “text_threshold” from 0.3 and 0.25 to 0.1 and 0.1. This means Grounding DINO will output more bounding box proposals for us to select from.
Here is the second frame, with the temporal consistency scores displayed:
Here is another example from the side camera view (145th frame):
Below are the segmentations for the same demo, but processed with the temporal-consistency scoring function.
Clearly, the tracking is much better now. Observe that the red block in Cam 0 (top right) is now segmented correctly even during manipulation and stacking. However, there are still some small errors. For example, at the start in the Cam 0 “Franka robot arm” view, the green block is segmented instead of the robot. This will be addressed in the next section with the addition of labels.Below are the FoundationPose results where every frame is conditioned on the improved, temporally-consistency segmentations from LangSAM.
Stack-Blocks with Temporal Consistency
Now, the model is able to track each block throughout the demo.
You may also notice that the coordinate systems for each box are now aligned, in contrast to the first FoundationPose video. I realized that since cubes have many axes of symmetry, the icosphere of pose initializations leads to random output orientations. I reduced the number of initial rotation guesses to a single identity matrix which results in consistent cube orientations and a ~150% speedup of FoundationPose.
FoundationPose + Labels
Occasionally, even the first-frame LangSAM segmentation is wrong, so temporal consistency can end up reinforcing an incorrect mask. Additionally, sometimes objects are occluded completely or leave the image entirely, making tracking impossible. Since we were shooting for a deadline and needed results quickly, I decided to manually add some labels to our collection of 60 demonstrations. With the help of ChatGPT, I wrote a labeling pipeline to step through each video and provide object bounding box labels and “stop tracking” labels at select frames.
Here are the segmentations for the same stack-blocks demo again. Now, the Cam 0 “Franka robot arm” segmentation is correct, even in the first frame.
Stack-Cups and Stack-Plates Tasks
With the stack-blocks task working, I ran the pipeline on two new tasks – stack-cups and stack-plates.
Here is FoundationPose on stack-plates without temporal consistency and labels:
Tracking of the plates fails when they are lifted out of the scene or occlude each other on the rack.Here are the results after adding temporal consistency and labels:
Stack-Plates Results
The labels that indicate when FoundationPose should stop and reinitialize tracking significantly improve the pose estimates.
Here is the before and after for the stack-cups task:
Stack-Cups Results
There’s much less of a difference, partially because the tracking already worked well without my modifications. I don’t know why FoundationPose succeeded here and failed on the blocks, since the tasks are basically identical and use similarly-sized objects. Perhaps the FoundationPose training dataset contained more objects like the cups.
Conclusion
We’re still looking for better solutions for real-world object pose estimation. Conditioning FoundationPose on temporally consistent bounding boxes greatly improved results for the stack-blocks task, while data annotations greatly improved results for the stack-plates task. However, the results are still far from perfect and manually providing data annotations for videos for multiple objects is not scalable. For those who are also interested in also using FoundationPose, here are some recommendations:
My Recommendations
For real-world object pose tracking, the best thing to use is a motion capture system. If that is not an option, I would recommend putting several AprilTags on each object and tracking them that way. If neither of those options work, then use FoundationPose. To obtain decent results with these models:
- Track large objects or move the camera closer to the scene
- Use the highest camera resolution
- Avoid occluding the tracked objects
- Avoid moving the tracked objects out of frame
- If you have a higher compute budget, try BundleSDF. BundleSDF takes longer to run for each video, but handles occlusions much better.
My recommendations regarding LangSAM are to:
- Choose objects that are distinct from other objects in the scene in terms of shape and color
- Spend time experimenting with different prompts
- Use an LLM to generate prompts to try
- Use bounding box prompting for SAM (instead of points)
Here is my fork of FoundationPose: https://github.com/jmcoholich/FoundationPose.
Here are more tips for running FoundationPose from the authors: https://github.com/NVlabs/FoundationPose/issues/44#issuecomment-2048141043 https://github.com/030422Lee/FoundationPose_manual
A huge thanks to the FoundationPose authors for developing and releasing this model! Also thank you to Justin Wit for helping me setup tasks and collect data for all the experiments shown.
References
Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. "Bert: Pre-training of deep bidirectional transformers for language understanding." In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pp. 4171-4186. 2019.
Kirillov, Alexander, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao et al. "Segment anything." In Proceedings of the IEEE/CVF international conference on computer vision, pp. 4015-4026. 2023.
Liu, Shilong, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang et al. "Grounding dino: Marrying dino with grounded pre-training for open-set object detection." In European Conference on Computer Vision, pp. 38-55. Cham: Springer Nature Switzerland, 2024.
Medeiros, Luca. 2023. lang-segment-anything. GitHub. https://github.com/luca-medeiros/lang-segment-anything.
Ravi, Nikhila, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr et al. "Sam 2: Segment anything in images and videos." arXiv preprint arXiv:2408.00714 (2024).
Wen, Bowen, Jonathan Tremblay, Valts Blukis, Stephen Tyree, Thomas Müller, Alex Evans, Dieter Fox, Jan Kautz, and Stan Birchfield. "Bundlesdf: Neural 6-dof tracking and 3d reconstruction of unknown objects." In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 606-617. 2023.
Wen, Bowen, Wei Yang, Jan Kautz, and Stan Birchfield. "Foundationpose: Unified 6d pose estimation and tracking of novel objects." In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 17868-17879. 2024.
Zhang, Hao, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M. Ni, and Heung-Yeung Shum. "Dino: Detr with improved denoising anchor boxes for end-to-end object detection." arXiv preprint arXiv:2203.03605 (2022).
Jeremiah Coholich
Robotics PhD Student
My research interests include deep learning, reinforcement learning, and legged robots.