 A proposed architecture for learning robust polices for real-world deployment
A proposed architecture for learning robust polices for real-world deploymentAbstract
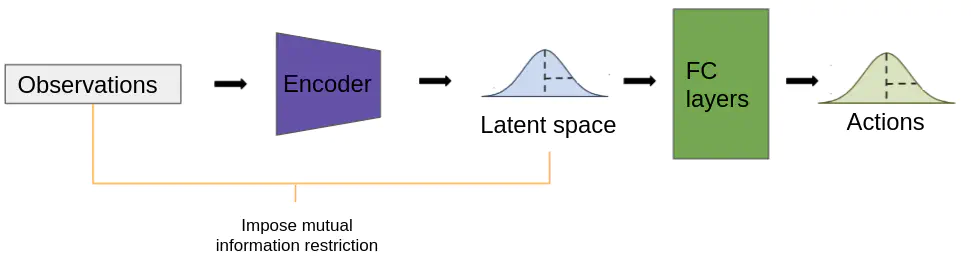
Transferring policies learned in simulation via reinforcement learning (RL) to the real world is a challenging research problem in robotics. In this study, the sim2real transfer method of three papers is examined. In [2], the RL agent learns a robust policy by limiting the observation size and using domain randomization. The sim2real method in [11] learns an adaptive policy conditioned on a latent space that implicitly encodes the physics parameters of its environment. Samples must be collected on the robot to learn a latent space corresponding to the physics of the real world. In [6], the authors also employ a learned latent space, but constrain the mutual information between the latent variables and the input. This ”information bottleneck” prevents the latent space from overfitting to the simulation physics parameters. Finally, I propose using the same information bottleneck approach on policy observations to learn a robust policy more effectively.
Jeremiah Coholich
Robotics PhD Student
My research interests include deep learning, reinforcement learning, and legged robots.